Naming is not a style preference. It is a schema.

Naming looks like a small detail in most codebases, but it quietly shapes how a system holds together. I realise that sounds grand for what most teams treat as a bike shedding exercise. "Should it be buyer_id or buyer_uuid?" "Should this field be called owner or created_by?" Most of those arguments go nowhere, because they're framed as a taste question: pick the better-sounding word and move on. But if you've ever tried to trace a concept through a backend and ended up opening six files before you were sure they were all referring to the same thing, you already know the disagreement isn't really about taste. It's about whether the system agrees with itself about what things are.
A friend of mine runs a small manufacturing shop. He once told me that the reason his warehouse works is that a bolt is called the same thing on the engineering drawing, on the bin it lives in, and on the invoice he sends the customer. When the names match, parts move. When they don't, someone somewhere in the building is doing a reconciliation. Reading a drawing, walking to a bin, looking for something that doesn't quite match, and eventually finding it. Every one of those reconciliations costs time, and none of them produce anything new.
Backend codebases work the same way. Take an MVC framework like Django: the bolt is an entity, an order, a buyer, a supplier, a document. The drawing is the database model. The bin is the serializer. The invoice is the URL that an external consumer sees. When all three agree, the system moves. When they don't, someone is reconciling. That someone is usually me, at eleven at night, trying to remember which layer renamed the thing.
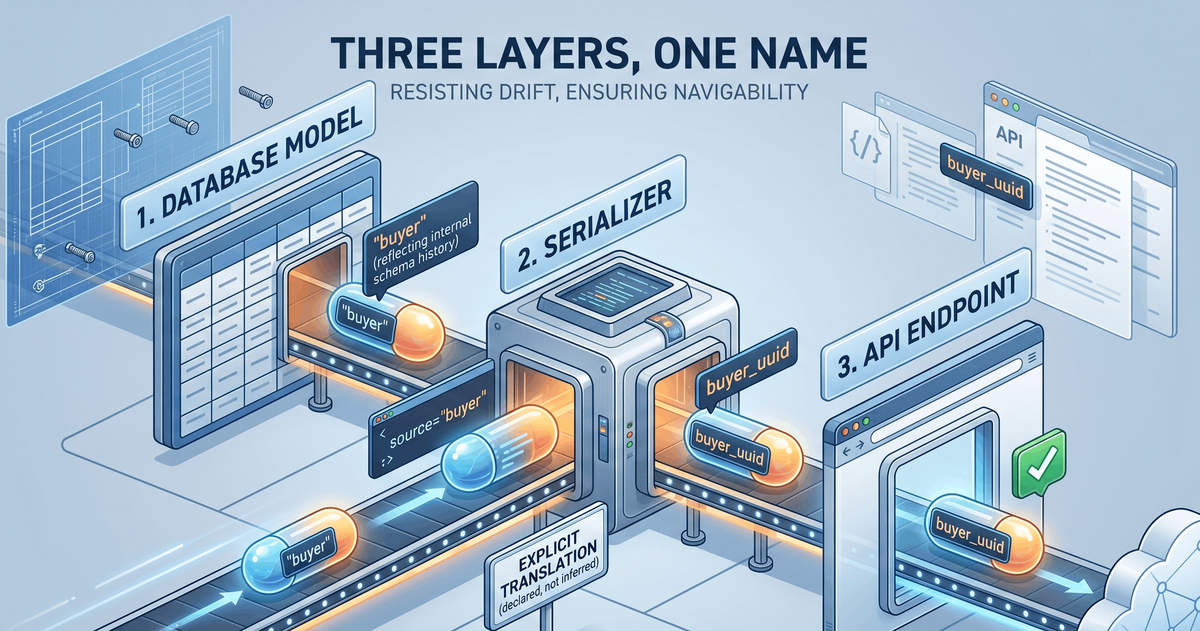
Three layers, one name
In an MVC-style backend, like Django, there are usually three primary places a name has to live.
The model is where the data actually exists. It has its own pressures: brevity, database conventions, years of schema history that nobody wants to migrate. The serializer is the wire format. It has different pressures: external readability, backward compatibility, the need to hide internal fields. And the endpoint is the public surface. It has yet another set of pressures: URL aesthetics, REST conventions, client library ergonomics.
Each of those layers wants to drift in its own direction. That is the problem. The model wants to be short. The serializer wants to be self-documenting. The URL wants to look tidy in a browser. Left alone, each layer will pick the locally optimal name, and by the end you have three names for one thing.
The job is to resist that drift. Or, when you can't, to make the translation explicit. Drift almost never happens in a single commit. It happens over time: in three commits over three months by three different people, each of whom made a locally reasonable choice.
Someone adds a new field. They call it owner, because that's the word the product spec used. Later, a serializer exposes it as created_by because that's clearer to an external consumer. Later still, a URL for filtering gets added: ?creator=.... None of those decisions was wrong on its own. The compound is.
Another common source of drift is abbreviations. Somebody decides merchant_of_record is too long and uses mor in a helper function. That would be fine if it stayed in the helper, but it never does. Within six months, mor is in three more files, and the codebase now has two names for the same concept, one of which is unsearchable unless you already know it exists.
What it costs, and what it saves
Think about the last debugging session you lost an afternoon to. If you're honest, a non-trivial percentage of that afternoon was probably orientation. Figuring out which version of the name referred to which thing. Mapping a field in the response to a column in the database. Tracing a URL back to a view back to a serializer back to a model. None of that is debugging. It's archaeology.
When the naming holds, archaeology goes away. The IDE search becomes a reliable navigation tool instead of something you have to interpret. A new engineer on the team asks "is this the same thing as that other thing" maybe twice in their first week instead of fifteen times. Code review gets shorter because reviewers stop spending attention on orientation and start spending it on logic. Generated OpenAPI schemas stay clean without a hand-maintained dictionary of overrides.
None of that is glamorous. No one ships a feature called "the buyer_uuid field is named the same thing in three places." But it is the kind of invisible work that compounds, and we pay interest on it either way. The choice is whether to pay up front or at eleven at night.
I want to be careful not to over-index on this. Consistency is a default, not a mandate. There are legitimate reasons a layer will use a different word than the layer below it. Public APIs sometimes speak the user's language, not the database's. Multi-tenant APIs sometimes disambiguate concepts that are collapsed internally. Security or compliance renames exist. None of that is drift. The difference between drift and a deliberate translation is that a deliberate translation is declared. Someone, in code, said "this is a different name, and here is why." Drift is when no-one said anything at all and the names diverged because gravity.
If you want a single rule of thumb, it is this: grep the identifier. If the trail breaks at a layer, that's a naming bug. Either the name should be the same on both sides, or the translation should be explicit enough that the break is obvious. A system with no name breaks is navigable. A system with declared breaks is navigable. A system with silent breaks is a tax on everyone who reads it.
Back to the bolt
The manufacturing shop my friend runs is not special. The reason it works is that someone, at some point, decided the bolt was going to be called the same thing everywhere, and then held the line on that decision every time a supplier catalog or a new drawing tool tried to rename it. That's the whole discipline.
We aren't doing anything more exotic in software. We have a model, a serializer, and an endpoint. They refer to the same underlying thing. If we let each layer drift toward its own locally optimal name, we end up running a reconciliation shop. If we hold the line, the system starts to read like one system instead of three things glued together.
A name that survives all three layers is not a naming win. It's a design that has nothing left to hide.
AI doesn’t fix ambiguity
This counts even more nowadays, in the era of AI-driven development. Models don’t understand your system, they infer it from patterns. When names hold, the system presents a consistent shape, and both humans and machines can move through it with confidence. When they don’t, the gaps get filled with guesses. In the end, the discipline is the same: either the system agrees with itself, or someone has to reconcile it.



